Somewhere to keep ...
things I do while learning.
Removing the human: Generative text.
Why wait for human input when you can just use Math.random()?
Site Hansard Blurter Twitter account, generating from the 1800 Hansard input.
Site A sample of generated blurts from the 1981-2004 Hansard data.
With all the machine leraning and artifical inteligence hype, why not just take the final step from stylometry and chain-following? Generate the seed from the set of all openers, and walk a random path.
We pick a sentence to tweet from a random starting point, an arbitrary number of continuations, and an end-of-sentence where overlaps key the transtitions. opens is simply an array, the others (middles and closes) are dictionaries keyed by the tail word-pair of the tweet-thus-far.
var opens=["The Minister is nodding", "I disagree with almost",...];
var middles={"get a":["reputation for","discount on", ...],
"are pledged":["to the","willingly by", ...]};
var closes={"may have":["brutal results.", "won again."],
"a little":["wide now.",...],...};
Generation of a tweet is then a series of Math.round(Math.random() multiplied by {opens|middles[key]|closes[key]}.length. The data sets gathered were small to begin with, a handful or records from the early 1800s (150,000+ approximate sentences). Latterly, the 13M+ line set from 1981-2004 worked on an 8Gb Mac but blew up from the naive implementation on a Rasberry Pi.
node defaults to a moderate heap and needs --max-old-space-size=2048 (2Gb) to run a trimmed 1981-2004 data set (just the first 5M lines) fails on a Raspberry Pi. I should use a database, but I wasn't going to start playing with mongo.
Attach the tweet-content generating script to a Twitter account via the API (I used the twit package). Throw invocations into a loop that tweets once per day on you Raspberry Pi and wait for something tenuously related to today's politics burp form the machine.
Make a second account. Have them born in 1951.
Clandestine fun through Markov chains

Constraints spark creativity.
Site I was born ... Romeo and Juliet style.
Aggressive reduction of the stylometry experiment as a teaching aid made something fun enough to record. The result is a predictive text engine to build on, with enough to start showing the fun you can have applying the result.
Starting again, with Romeo and Juliet (in RandJ.txt) we build the dictionary of possible following words for a given lead word. This time we did it all at the command line. No scikit-learn or TensorFlow here as you might find on YouTube. Just a few lines of bash and a handful of JavaScript to prepare the dictionary.
cat RandJ.txt | tr '[:upper:]' '[:lower:]' | <-- normalise to lowercase
tr -d '[:punct:]' | <-- ditch punctuation
tr -d \\r | <-- normalise CRLF
tr \ \\n | <-- split words one per line
sed -e '/^$/d' <-- delete empty lines
> words.in.order <-- save a column linearised copy
words.in.order looks like:
the project gutenberg ebook of romeo and juliet by william ...
Turn this into a list of frequency sorted word pairs where the second word follows the first. Add syntax sugar so these word pairs read as JSON objects with key/value pairs to then collapse the left-hand sides.
wc words.in.order <-- how many left-hand-sides?
28970 28970 149169 words.in.order
tail -28969 words.in.order > second.words <-- take the whole text bar one word
to make the right hand sides.
paste -d: words.in.order second.words | <-- paste the left and right hand sides
sort | <-- order them by the left hand sides
uniq -c | <-- collapse duplicates and count
sort -rn | <-- sort (descending) by count
sed -e 's/^.* /{"/;s/:/":"/;s/$/"}/' <-- drop numbers, have served purpose,
decorate with curlys and quotes
> all.wordpairs.js <-- save
all worpairs.js is a well formed list of JSON key value pairs:
{"of":"the"}
{"i":"will"}
{"in":"the"}
{"project":"gutenbergtm"} <-- side effect of untrimmed input
{"i":"am"}
{"to":"the"}
{"of":"this"}
{"it":"is"}
{"i":"have"}
{"with":"the"}
{"project":"gutenberg"} <-- side effect of untrimmed input
{"the":"project"} <-- side effect of untrimmed input
{"is":"the"}
{"for":"the"}
{"thou":"art"}
For each left hand side (key) we push the right hand side (value) to form the dictionary -- testing for the case that the left had side has a structure to push. Pseudo code of full collapser:
var dict={}; <-- initialise an empty dictionary
for each line l in all.wordpais.js
o=JSON.parse(l); <-- parse into a key/value object
key=Object.keys(o)[0]; <-- take the first key
if (typeof(dict[key] == "undefined") { <-- this left hand side is novel
dict[key]=[]; <-- initialise the left hand side
}
dict[key].push(o[key]); <-- append this right had side
Processing all.wordpairs.js collapses to the form:
dict={
...
"born":["to", "some"],
...
"some":["other", "of", "say", "noise", "ill", "word", "want", "villanous", "vile", "twenty", "that", "supper", "strange", "spite", "special", "shall", "punished", "private", "present", "poison", "paris", "others", "occasion", "new", "misadventure", "minute", "meteor", "merry", "means", "mean", "juliet", "joyful", "house", "hours", "hour", "half", "grief", "great", "good", "fiveandtwenty", "festival", "distemprature", "consequence", "confidence", "comfort", "business", "aquavitae", "aqua", "and"],
...
};
Moving to consumption in the browser, this is simply a matter of emitting a button for each word from a given state, and appending the selected word to the message:
var step = function(w) {
document.getElementById('message') += ' ' + w;
var buttons=document.getElementById('buttons');
buttons = '';
for (var i in dict[w]) {
var nw = dict[w][i];
buttons += ' <button; + <-- create a button
; onclick="step(\''+ nw +'\');">; + <-- sets up next step
nw + '</button>';
}
}
With the word wherefore this results in the button list, of descending frequency in the text, and with the most likely famous in last place:
The graph JIRA didn't offer
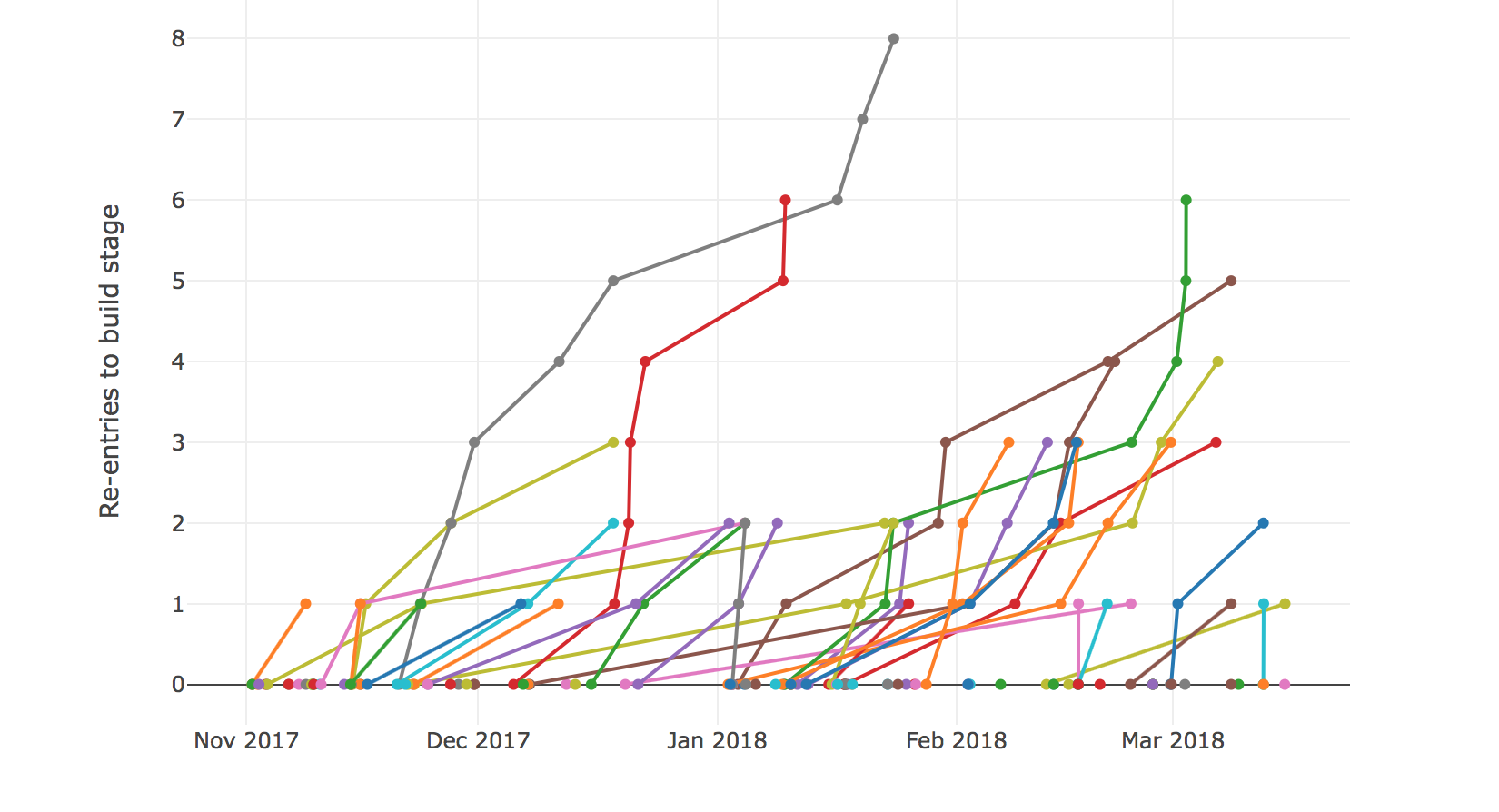
Tickets going back into build over time.
Site Three projects measured.
Progress concerns on a project tracked in JIRA weren't being represented in the standard set of visualisations like the cumulative flow graph. I wanted to see if the data stood up to the anecdotal mood outbursts. First I counted the number of times a ticket was pushed back from Test to Build. There are JIRA plugin based solutions using custom fileds, and JQL/Webhook alternatives. These would give a singular field report, I don't speak any JIRA and I was after a broader picture. What I could get was the ticket data in JSON via the JIRA REST API. The first task was to get all the ticket IDs for a given project. Setting maxResults to -1 returns all results.
curl -s -u $user:$pass -X GET -H "Content-Type: application/json" "https://$your.jira.server/jira/rest/api/2/search?jql=project=$project&maxResults=-1" | jq '.issues[] | .key' "D-517" "D-516" "D-515" "D-514" "D-513" ...
For all transitions of an individual ticket get the extended changelog detail.
curl -s -u $user:$pass -X GET -H "Content-Type: application/json" "https://$your.jira.server/jira/rest/api/2/issue/$ticket?expand=changelog"
Initially, I just wanted to test the claim that a large number of ticket were being returned form the Test column to Build. Using jq plus grep to filter the transitions we want then count with wc.
curl ...$ticket... | jq '.changelog.histories[] | .items[] | [.toString, .fromString]' | jq '(.[0]=="Build" and .[1]=="Test")' | grep true | wc -l
Iterating this over the tickets filtering for those with two or more pushbacks generates a summary.
cat tickets | while read ticket do ./count.pushbacks.sh $ticket | grep :[2-9] done D-107 Test to Build pushbacks:3 D-84 Test to Build pushbacks:2 D-71 Test to Build pushbacks:2 D-53 Test to Build pushbacks:4 D-50 Test to Build pushbacks:3 D-47 Test to Build pushbacks:2 ...
This gave rise to a number of questions when thinking about the progress a team is making on a project (improving over time) and whether this could be used to compare projects/teams.
A project's colective Test-to-Build rejections are still too close -- they cause a knee-jerk blame on developers. So I dialed back to simply counting the number of times a ticket enters Build and tracking that over time. Tickets can enter build form any direction (bouncing back to a requirement refinement stage or returning from somewhere downstream post-build). I think it makes an interesting measure of the management and execution of tickets. It's perfectly expected for some tickets to return to the Build stage if you're working at pace and trying to make a minimum increment on a product that's evolving. The question is, what do the stats for a team pushing hard look like compared to a team that's struggling to make the grade?
Returning to the Food Standards Agency
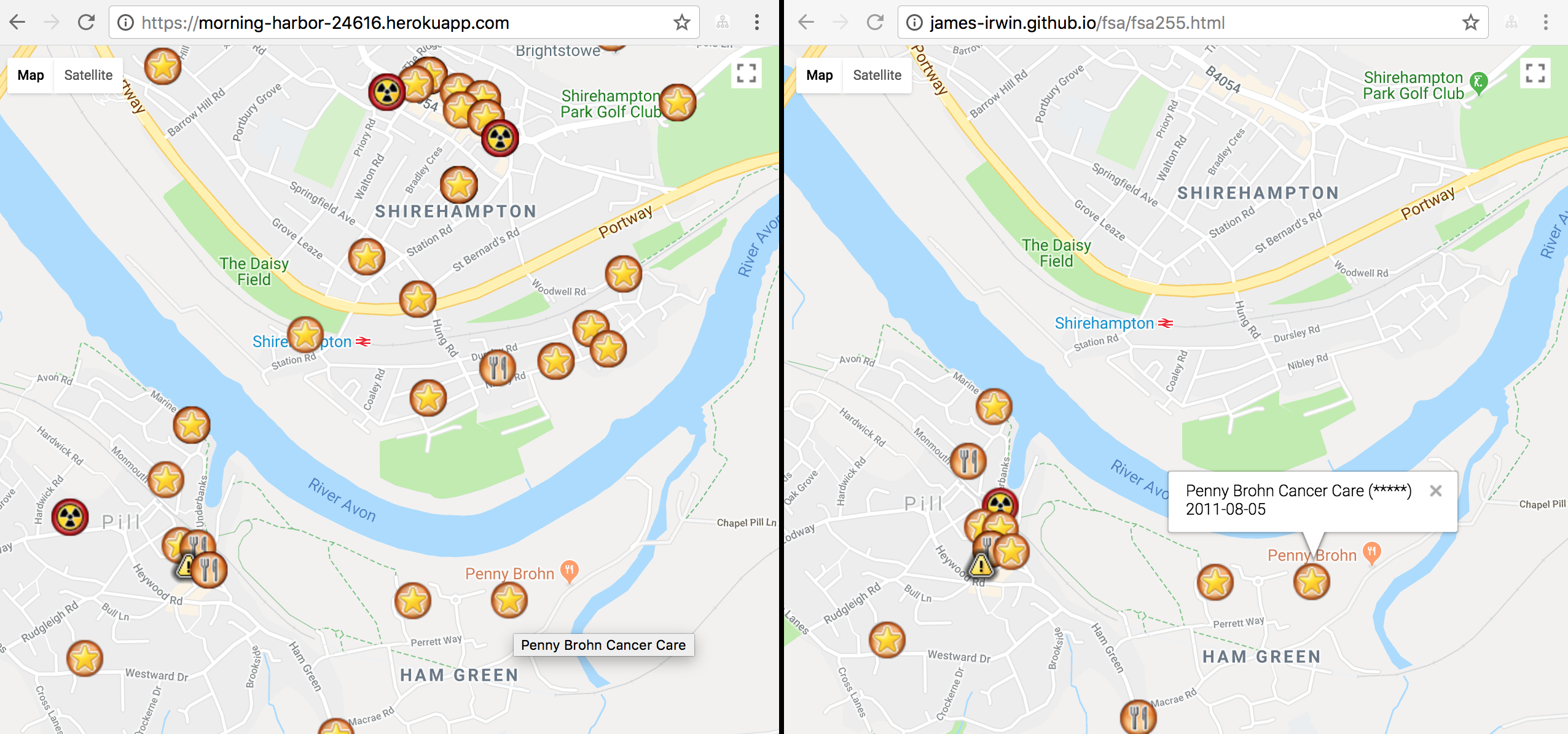
Map boundaries (left) rather than county boundaries (right) define what ratings are pinned to the map.
Site Heroku hosted Javascript app.
JavaScript to generate dynamic set over Google's mapping API.
Dissatisfied with the static first swing at pinning the FSA rankings on a map, I wanted to dynamically pin the food outlets based on the boundaries of a a map. This switches the load of thousands of pins for the county to however many were within the selected visible area. County border problems taken care of at the same time.
The FSA API offers a boundary based query defined by distance from a centre, however I was looking to make use of the bounding box API in elastic search. This was akin to the map of New York.
The Heroku site is stand-alone with a simple loop through all the ratings data that will return restaurant ratings to pin to the map. The process involved collecting all the FHRSID numbers; collecting the rating and details for each rated location; and then trimming it to that required to just mark the pin on the map.
Collecting all the IDs was a two step process. First get the first page of basic results with one record per page.
curl -XGET -H "accept: application/json" -H "x-api-version: 2" "http://api.ratings.food.gov.uk/Establishments/basic/1/1"
The key takeaway is the response component indicating the number of pages in the set.
{
"establishments": [
{
"FHRSID": 9228,
...
}
],
"meta": {
...
"totalCount": 525016, <-- this is the number we're looking for
...
},
...
}
Collect all 90Mb of basic results to enumerate all FHRSIDs by requesting the first page with $meta.totalCount items per page
curl -XGET -H "accept: application/json" -H "x-api-version: 2" "http://api.ratings.food.gov.uk/Establishments/basic/1/$totalCount"
{
"establishments": [
{
"FHRSID": 9228,
"LocalAuthorityBusinessID": "03850/0050/0/000",
"BusinessName": "\"A\" Squadron, Scottish And North Irish Yeomanry",
"BusinessType": null,
"RatingValue": "Pass",
"RatingDate": "2016-01-20T00:00:00",
"links": []
},
{
"FHRSID": 134047,
"LocalAuthorityBusinessID": "67154",
"BusinessName": "\"Buttylicious\"",
"BusinessType": null,
"RatingValue": "4",
"RatingDate": "2017-07-20T00:00:00",
"links": []
},
{
...
Collecting one full record for the loation uses the simple FSA API
curl -XGET -H "accept: application/json" -H "x-api-version: 2" "http://api.ratings.food.gov.uk/Establishments/1000011"
Returns the fourty-four line record
{
"FHRSID": 1000011,
"LocalAuthorityBusinessID": "INSPF/17/209773",
"BusinessName": "Killer Tomato",
"BusinessType": "Restaurant/Cafe/Canteen",
"BusinessTypeID": 1,
"AddressLine1": "Ground Floor",
"AddressLine2": "275 Portobello Road",
"AddressLine3": "LONDON",
"AddressLine4": "",
"PostCode": "W11 1LR",
"Phone": "",
"RatingValue": "5",
"RatingKey": "fhrs_5_en-gb",
"RatingDate": "2017-11-08T00:00:00",
"LocalAuthorityCode": "520",
"LocalAuthorityName": "Kensington and Chelsea",
"LocalAuthorityWebSite": "http://www.rbkc.gov.uk",
"LocalAuthorityEmailAddress": "food.hygiene@rbkc.gov.uk",
"scores": {
"Hygiene": 0,
"Structural": 5,
"ConfidenceInManagement": 5
},
"SchemeType": "FHRS",
"geocode": {
"longitude": "-0.206798002123833",
"latitude": "51.5178604125977"
},
...
}
This is trimmed and stored in a large JSON array to be returned from bounding box based searches used by the map object's idle listener.
curl "https://morning-harbor-24616.herokuapp.com/LAT=51.518&lat=51.5175&LON=-0.20678&lon=-0.2068"
The Killer Tomato is one of three in this tiny area
{
"params": {
"good": true,
"LAT": 51.518,
"lat": 51.5175,
"LON": -0.20678,
"lon": -0.2068
},
"found": [
{
"BusinessName": "Killer Tomato",
"RatingValue": 5,
"position": {
"lat": 51.5178604125977,
"lon": -0.206798002123833
}
},
{
"BusinessName": "Portobello Gardens",
"RatingValue": 5,
"position": {
"lat": 51.51786,
"lon": -0.206798
}
},
{
"BusinessName": "BRT Vinyl Cafe",
"RatingValue": 1,
"position": {
"lat": 51.517861,
"lon": -0.206798
}
}
],
"total": 3
}
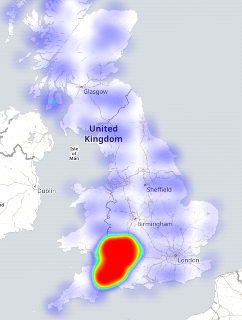
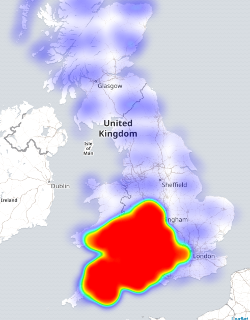
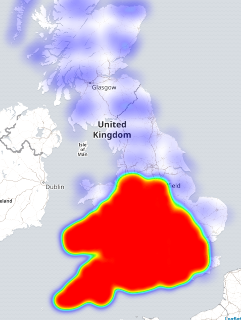
Getaway driving
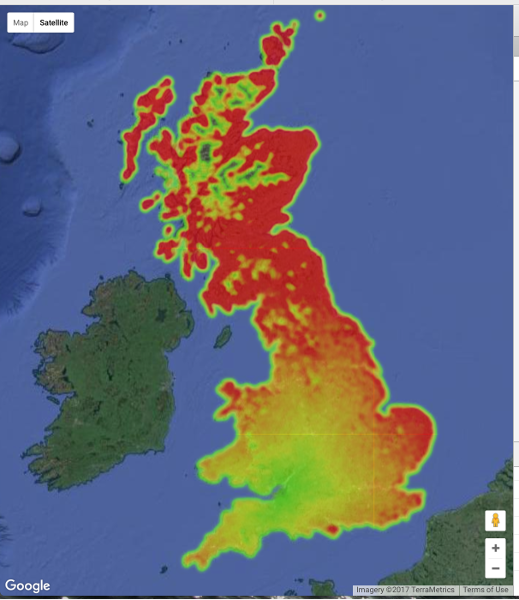
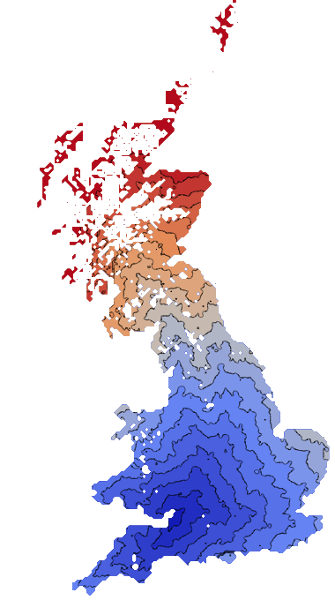
Wondering about day trip options with a budget of only 2500 drive-time lookups per day with the google API. Distilled the UK into about a nine thousand point grid (a week of free scraping) by taking the Code-Point Open data and finding the middle-most of each 5km box.
Four days of burning my quota to get driving distance and do a lat/long
lookup (too lazy to calculate form the OS gridpoint):

There were a few unroutable destinations. Naturally remote places included a fair few in islands off the coast or in a loch of Scotland, off Wales, and off Cornwall. A fair bit of the Shetland Islands were routable bar these. Novel places that wouldn't route were a Parrot Sanctuary and a cement and rubble company.
There's a fair bit of Scotland without enough postcodes to request a route. You can see the data grid by zooming in on the google heatmap.
Fitness data
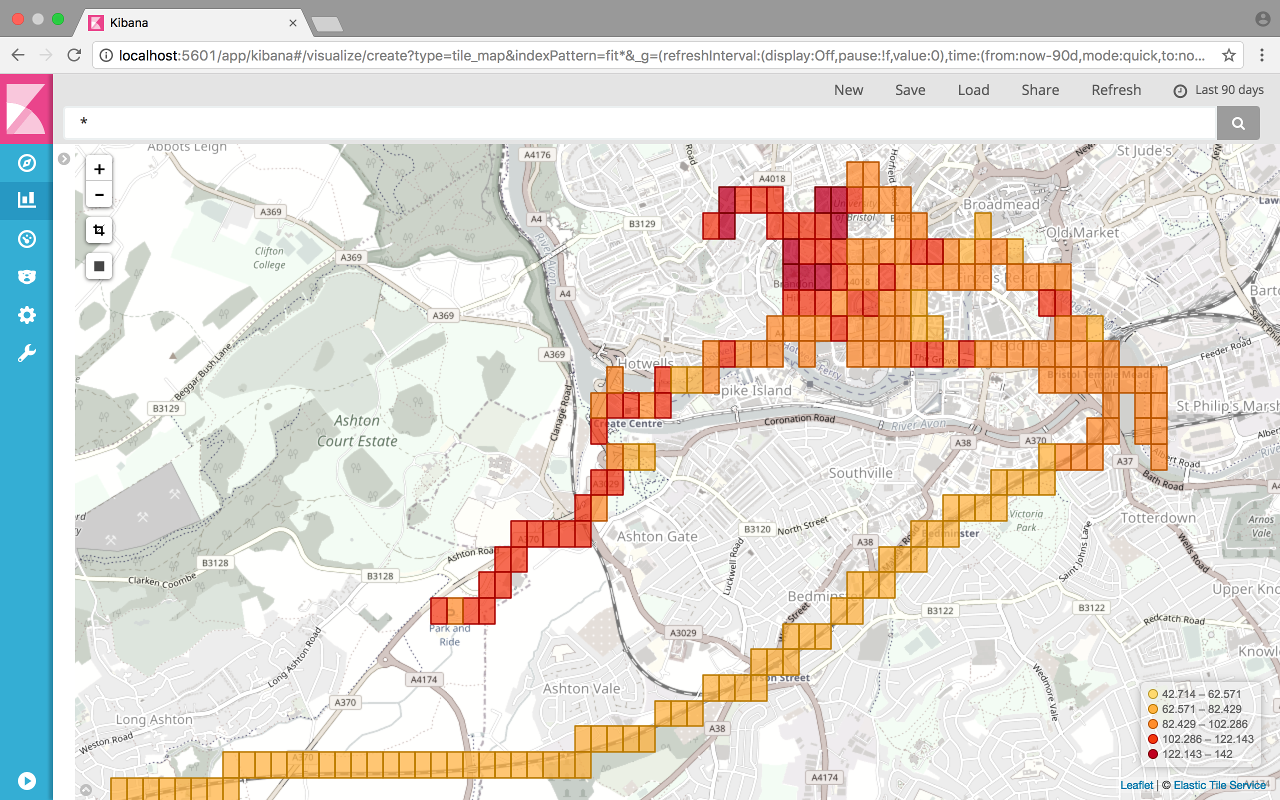
Heart rate nice and low on the train but walking to the park and ride, while faster than the bus that day, was a fair trek. My heart rate looks like a terrain proxy.
Python & Javascript to ETL Garmin or Strava files into Elasticsearch.
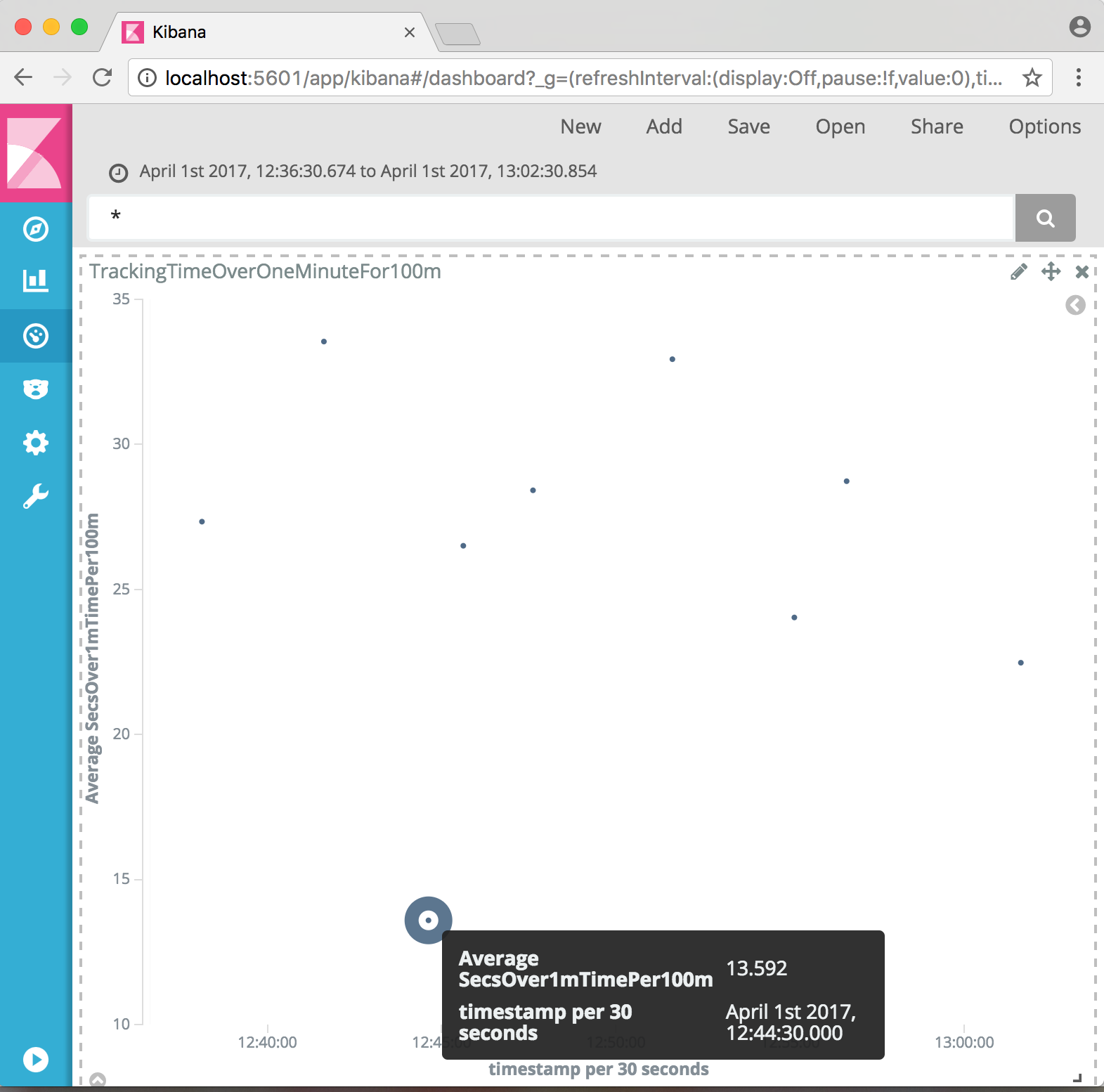
My goal is to swim 100m in one minute. Practice is what will count, but tracking how well I'm doing is interesting. There's the corporate Garmin connect and Stephane's Swimming Watch tools to look at your stats. However, there's a tonne more data coming out of a fitness watch. And I need to practice a little more ETL.
The Garmin watches turn out a FIT format file that is licenced but available to developers through an SDK. The code includes a patch to the SDK example (cpp/examples/decodeMac) to emit something more JSON-like to feed into a python loader for elastic search.
The Strava downloads are GPX format XML files. These are converted with a little Node/Javascript before another python loader for elastic search.
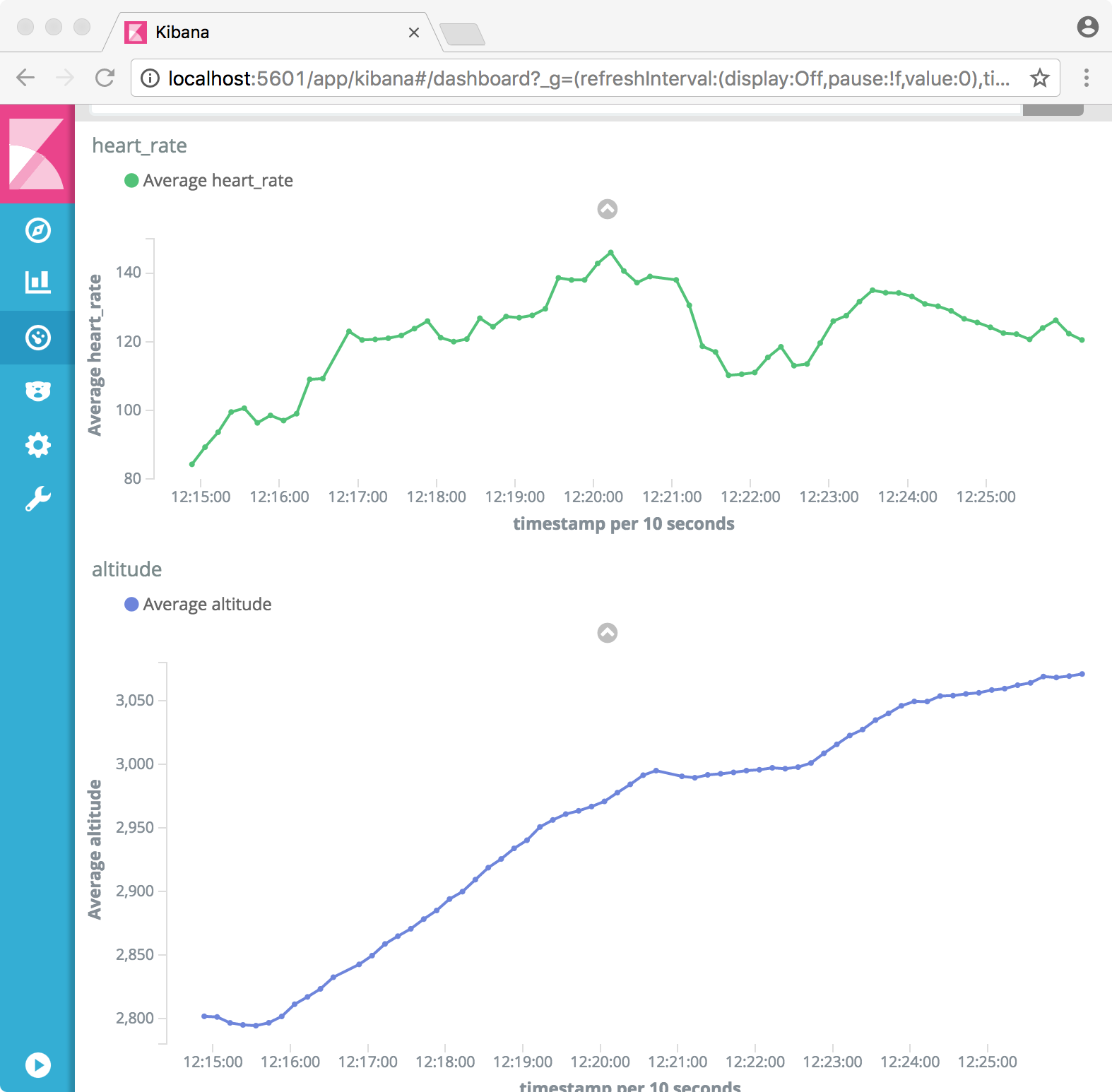
Just to make sure the data is loaded, a quick check with proper science says the first five minutes of walking to the pool shows altitude causing my heart rate ;)
The goal measurement is done in Kibana as a scripted field from the Garmin avg_speed field (milimeters per second).
(doc['avg_speed'].value==0.0)?0.0:((100.0/(doc['avg_speed'].value/1000.0))-60.0)gives the number of seconds I'm over the pace of one minute for 100m. First swim with a cold and watch that broke on its first outing in an odd-length pool but I have numbers!
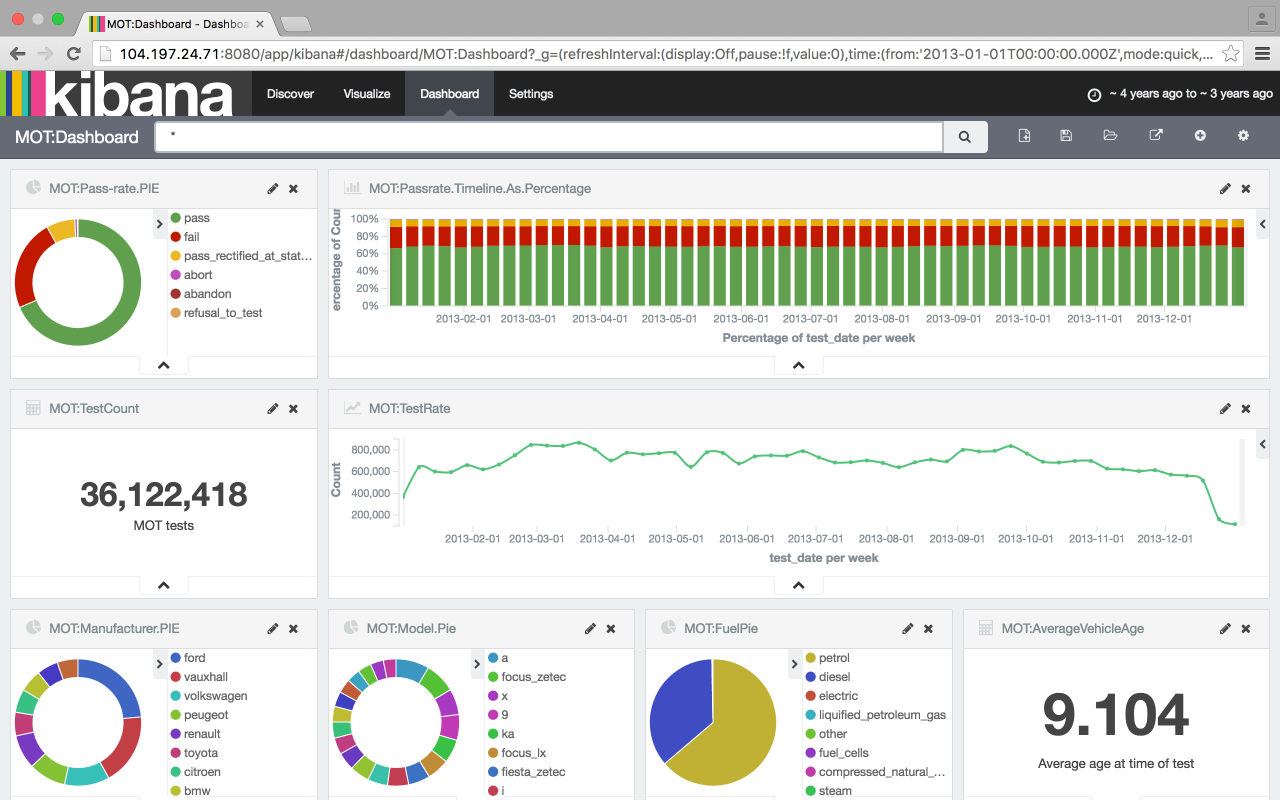
Vehicle test result dashboard
I didn't know the average vehicle was over nine-years old on the day it was put in for its MOT.
I needed to write an ETL in Python, and I wanted to start to use Kibana in anger. Python seems inescapable and I spent a few days trying to get to grip with the basics. Unlike the other visualisations, Kibana runs as a live service, atop an equally live Elasticsearch instance. After running on my laptop, I could then re-benchmark and host this on a cloud service for demonstrations.
I took the 2013 results data as this was the most recent data set and at 36m rows was a reasonable sized sample. The ETL code, like all the others, basically takes one line at a time from the CSV file and turns it into a Python dict. These are aggregated and pushed into Elastic search through the bulk interface. The (single threaded, single buffered) job takes an hour on my macbook and two hours on a two-core AWS instance. It took an hour longer on a Google Compute instance but I wasn't really sure I was doing it right
I loaded the data from the compressed file (and stripped the UNCLASSIFIED vehicles) to minimise read-bandwidth and disk space
$> mkfifo data.pipe $> gunzip -c data/test_results.gz | sed -e "/UNCLASSIFIED/d" > data.pipe & $> etl/MOT.csv.to.es.py data.pipe
To get satisfactory dashboard performance, I ended up choosing a four core instance (n1-highcpu-4) with 3.6 GB memory for the Elastic server and a simple one-core (n1-standard-1) for the Kibana server. The loaded Elastic index was about 4Gb and the Java runtime never used all the RAM. This costs about 20p per hour to run.
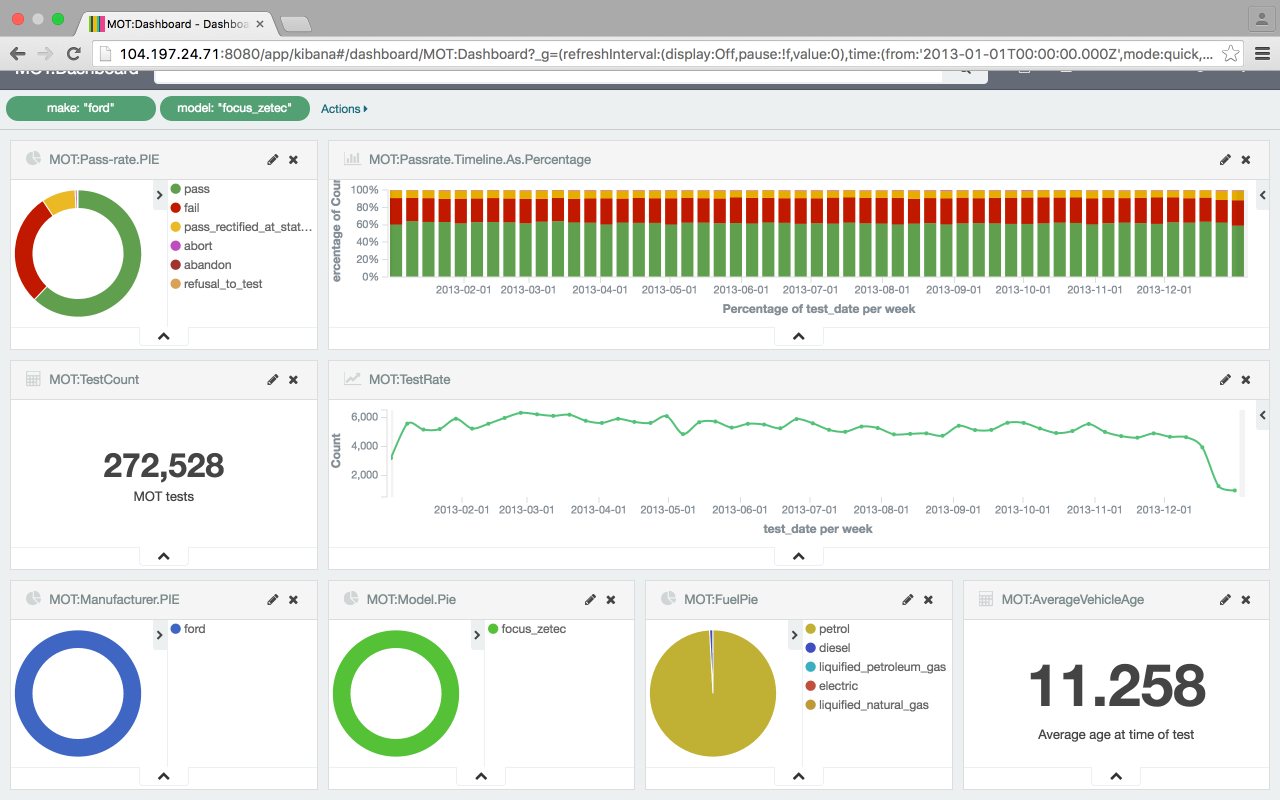
The most popular vehicle tested was the Ford Focus Zetec, filtered with two clicks on the pie charts and a wait of a couple of seconds as the 36m rows are processed. They're generally two years older, and fail more often than the average vehicle tested.
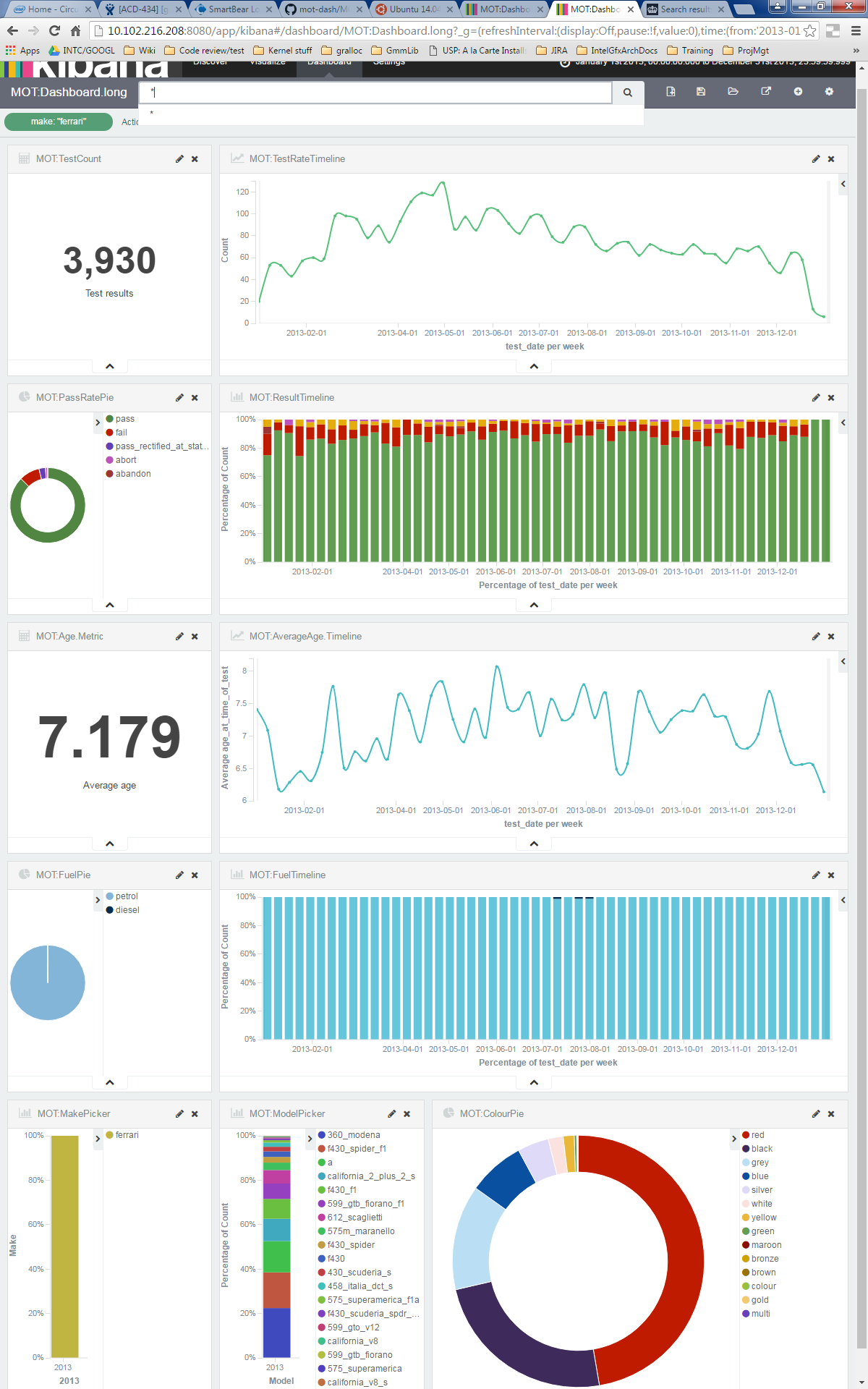
Ferraris, on the other hand, are rarer, younger and fail their MOTs less. The time that Ferraris are tested, biased towards the end of winter and spring suggests, perhaps, these are summer cars. Clearly red, is the colour for your Ferrari. Somehow, there are a couple of MOT records for diesel Ferraris?
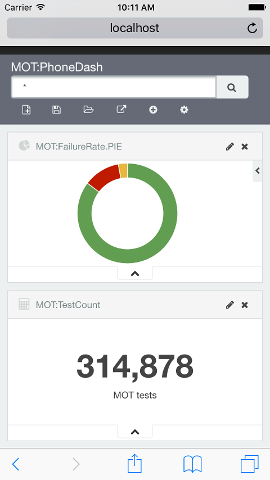
A summary metrics dashboard showing the data for two days fits nicely on a phone. The beauty of Kibana and Elasticsearch setup like this means a live feed into into Elastic permits auto-refresh (5 second) updates to trends of metrics that are operationally critical as I was able to see when developing the dashboard and loading the 36m rows simultaneously.
Prescription trends
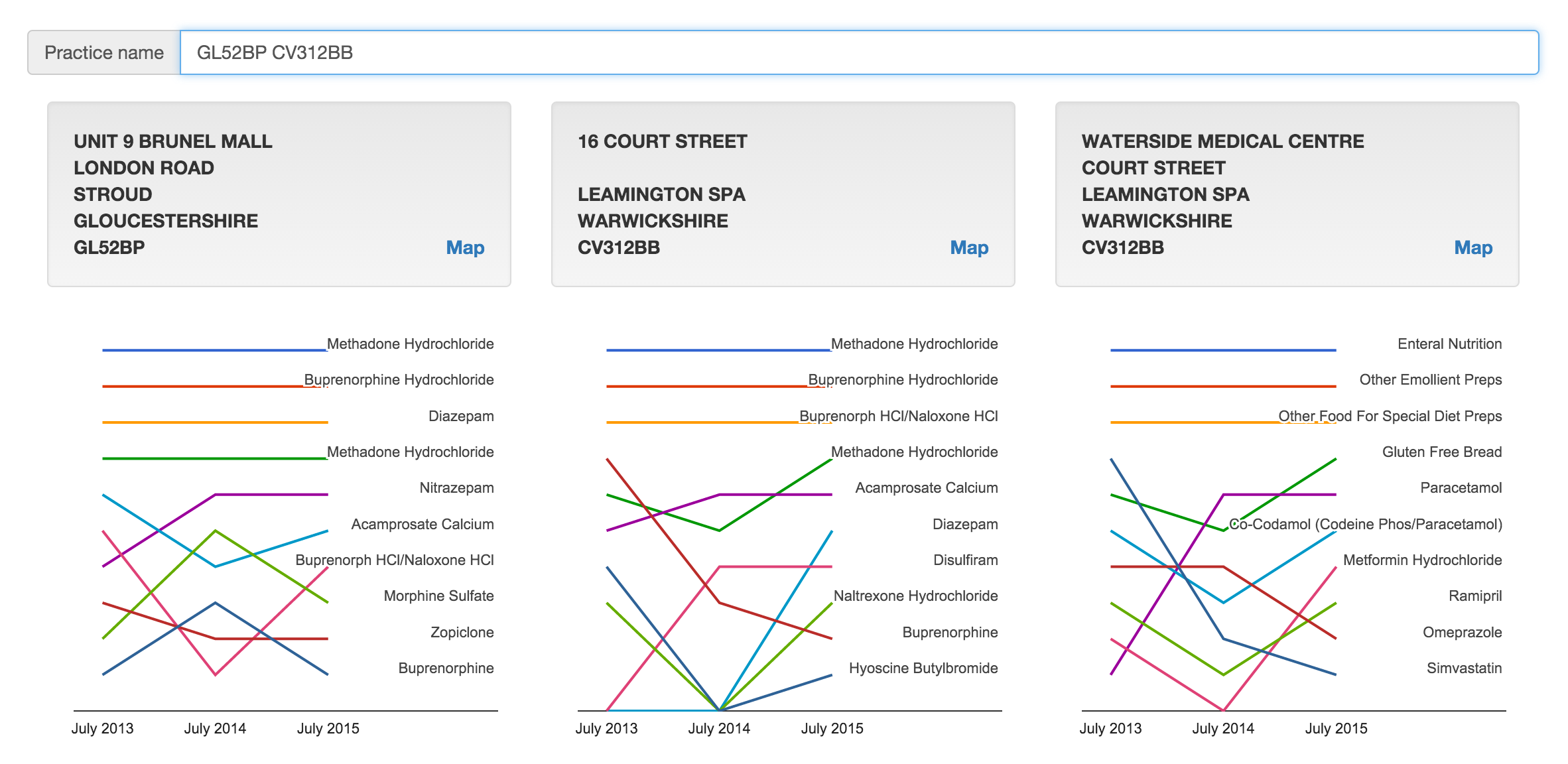
I wanted to know what we were medicating our prisoners with. Then I wanted to see the historical trending top ten things written there. Type 'HMP' in the search box to see.
Analysing three times as much data as the prescription drug map below (over thirty million rows) and trending the top ten with a trivial search by practice address. Slopegraphs in the league position style rather than the prescribed quantity show relative positions rather than relative volume.
Top drug writers
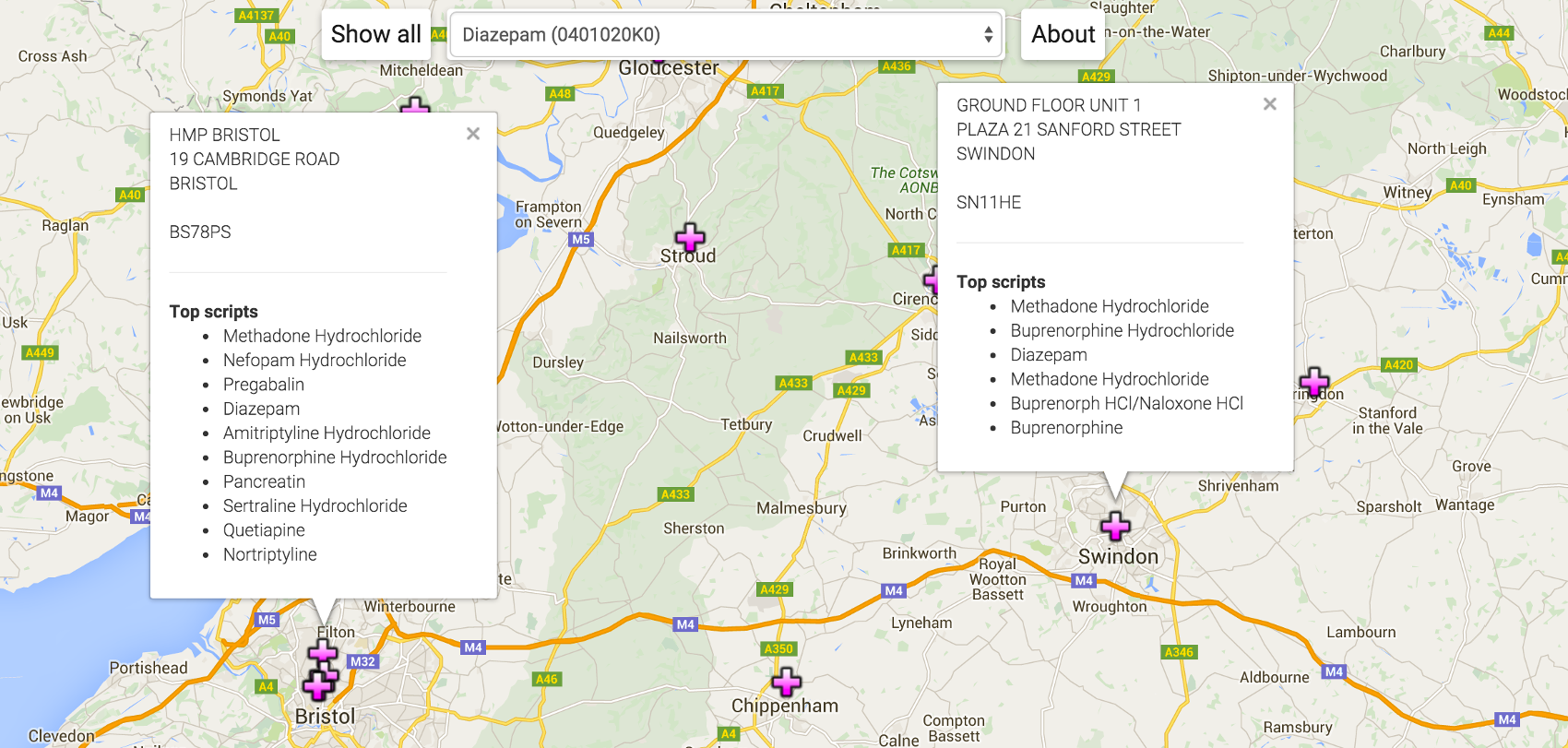
Is the surgery opposite the watersports park still the top place for dispensing entonox? What are we mostly medicating prisoners with?
Look at which practice/pharmacy writes the most of a given drug.
More JavaScript in the client, with the google maps API, and a proper aggregation in elastic search. The key structure is the practice record:
var practices = { ...
"Y02307": {
"latlng":{"lat":51.4806202,"lng":-2.590658},
"list":["0410030C0","0407010P0","0408010AE","0401020K0",
"0403010B0","0410030A0","0109040N0","0403030Q0",
"0402010AB","0403010V0"],
"address":["HMP BRISTOL","19 CAMBRIDGE ROAD","BRISTOL","","BS78PS"]
},
...
};
The practice ID is a foreign key in the source data set joining the prescription records to the address. I can use this when keying from the drug record below. Y02307 is the prison in Bristol. I used google's geocoder to generate and cache the latitude & longitude -- in batches because of the 2,500 per day limit. The list is the top ten, in decreasing order, BNF codes for the drugs prescribed by this practice. For comparison, the aggregation in SQL
sql> select bnf, sum(quantity) q from prescriptions where practice='Y02307'
group by bnf order by q desc limit 10;
Is about what I get from the elastic aggregation
$> curl 'localhost:9200/_search?q=practice:Y02307&size=0'
-d '{
"aggs": {
"by_drug": {
"terms": {
"field": "bnf",
"order" : {"total_quantity":"desc"}
},
"aggs": {
"total_quantity": {"sum": {"field": "quantity"}}
}
}
}
}'
The source data provides
readable
BNF translations for non-medics.
For the drug-to-map client, I have a similar but inverted
elastic aggregation.
This
is the top ten locations prescribing a given BNF.
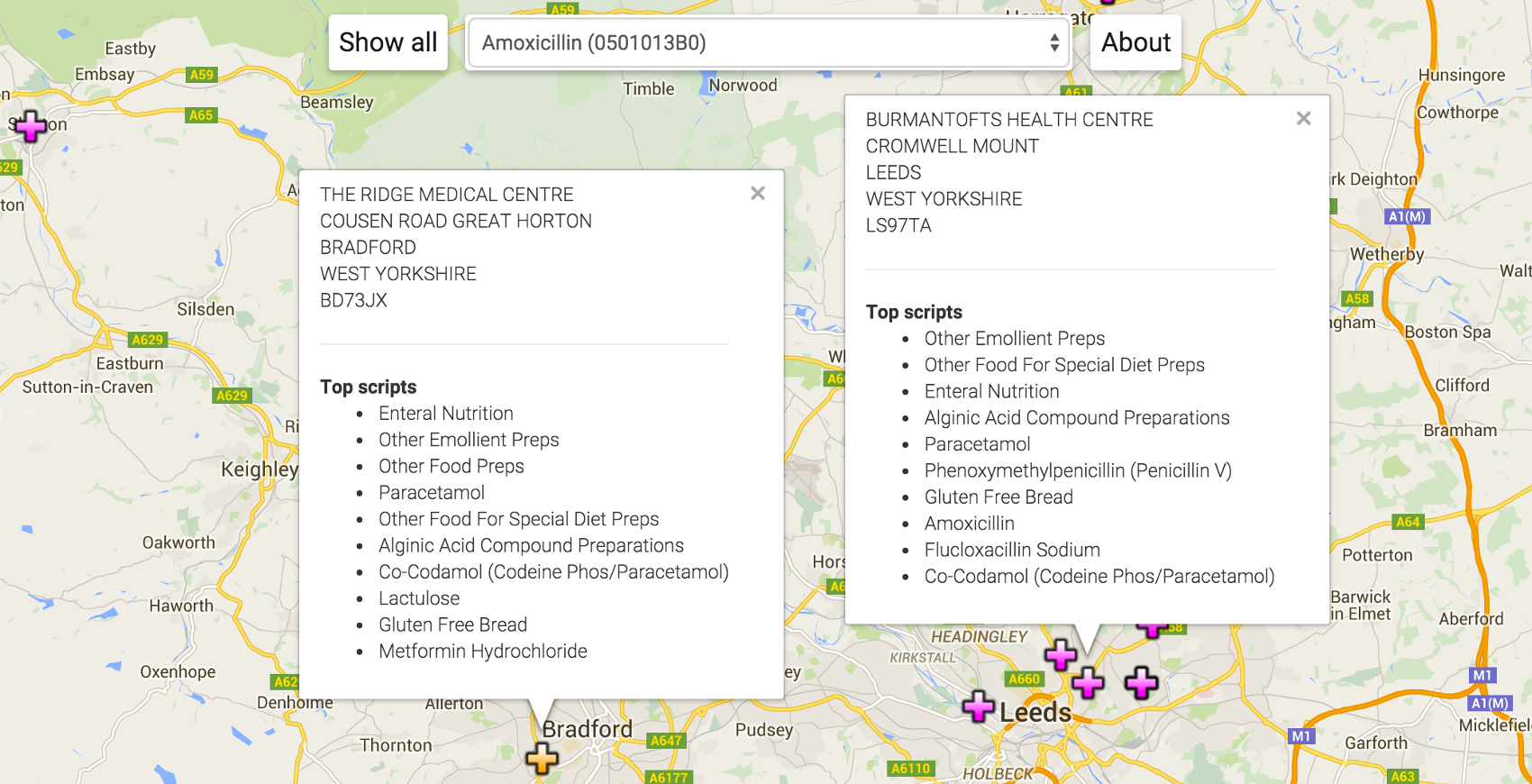 The Ridge Medical Centre writes more Amoxycillin than Burmantofts Health Centre
even though Amoxycillin is in the top ten things written at Burmantofts and not
in the top ten at Ridge. What's not shown is how many patients each practice is
serving.
The Ridge Medical Centre writes more Amoxycillin than Burmantofts Health Centre
even though Amoxycillin is in the top ten things written at Burmantofts and not
in the top ten at Ridge. What's not shown is how many patients each practice is
serving.
Stylometry & stylo-sympathy
I wondered how real stylometry might be and, better than that, could a machine help me write sympathetically in a given style? It arose from wondering about simultaneous multiple auto-suggest feeds and the request to not be quoted at length.
Write-like a few classics and compare them too.
JavaScript to generate word-distribution distillates; compare them and consume them.
I started with a body of standard texts: The King James Bible and the complete works of Shakespeare. I'd used both before as sources of word streams for benchmarking. Before analysing, I picked up a couple more samples that I might want to compare which meant all of Jane Austen and Bronte's Shirley to go with Shakespeare; an English translation of the Koran and an English translation of the Mahabharata of Krishna to weigh against a partitioned Bible (old and new testaments). The first step was to distill the text into something to use for both auto-suggesting and a basis for the comparison operation. The end resut was a Markov- chain like structure:
residue = ["word_1": ["following_word_1.1", "following_word_1.2", ... ],
"word_2": ["following_word_2.1", "following_word_2.2", ... ], ...
]
Where the words in the structure above are frequency sorted. I dropped the occurence counts for precise distributions and assumed a common (power-) curve for simplicity.
First to use the output were the auto-suggesters based on Nicholas Zakas' tutorial. Using a simple probability distributon function to pick the next word, iterated a few times and while I typed, a satisfactory prompt came from the suggester.
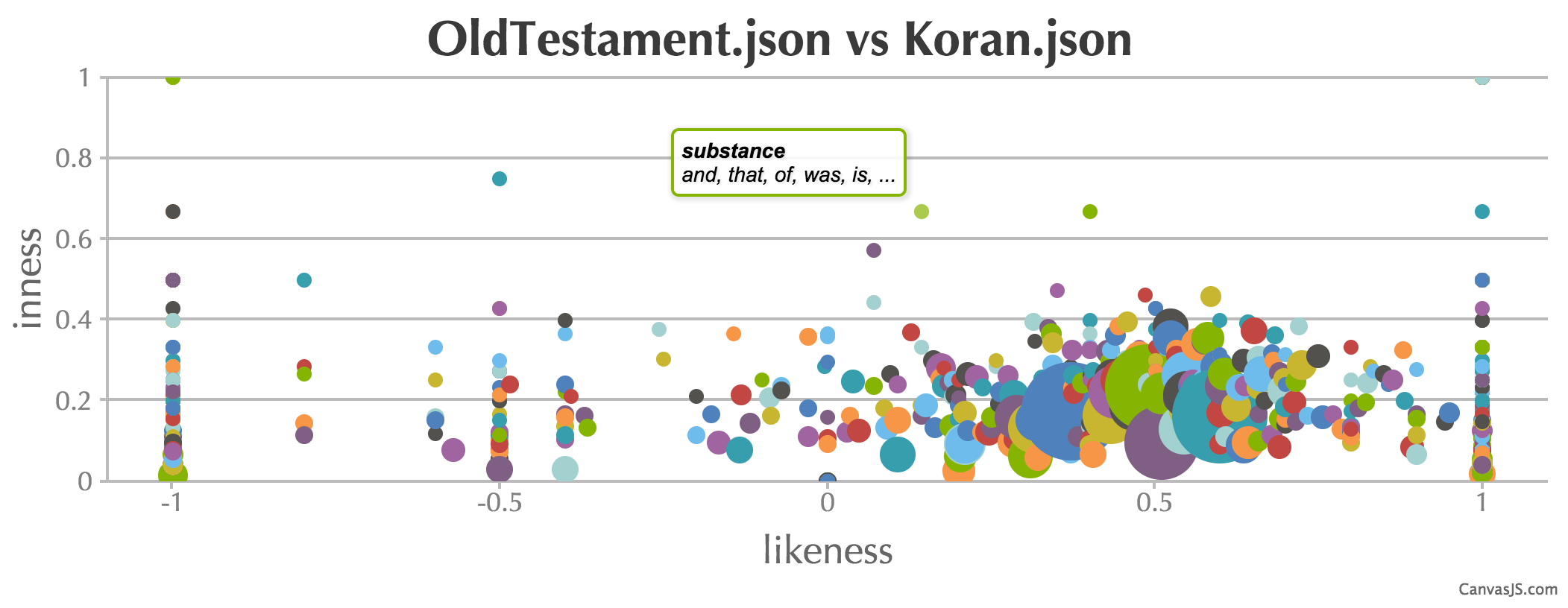
To compare two Markov-chains -- I haven't read anything about how stylometry is done properly -- I used a three dimensional metric that I could bubble-chart using CanvasJS charts for a change. The size of the intersection of two word lists as a percentage of the union is the y-axis (inness) and the absolute size of the intersection is the bubble size. This is to give an idea of the commonality between two texts. This doesn't eliminate inescapable common word- pairs of a written language but might give a sense of overlap. The third dimension (x-axis in the example) is the frequency order comparison (likeness) computed as a rank correlation using the simple statistics library. Both the parallel suggesters and the bubble-chart with annotations are intersting to play with as a result.
Sankey diagrams of Enron email via Elasticsearch
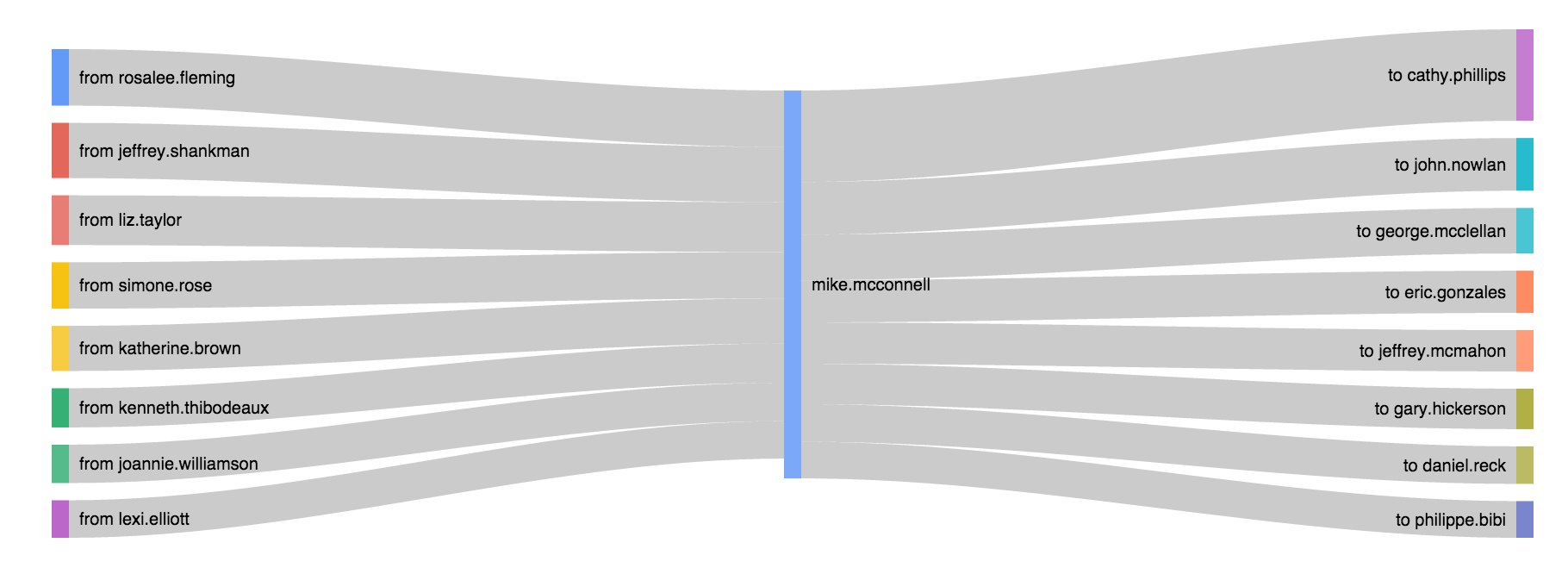
An excuse to draw Sankey diagrams and learn to do aggregations in Elasticsearch. The Enron mail corpus fit and was plenty less trendy than twitter/facebook feeds. Check out Vince Kaminski (an objector to the practices with a fat cc: pipe to himself outside of Enron) or Rosalee Flemming (Ken Lay's assistant, a broadcast beacon to the top brass).
Sankey diagrams (with clickable fudge).
JavaScript to generate Sankey diagrams from aggregates collected from Elasticsearch.
The tarball of data needed loading into Elasticsearch. I used mailparser in processing each file to generate an Elasticsearch entry demultiplexing multiple names on the To: line.
node mail.to.es.js .../enron/enron_mail_20110402/maildir/crandell-s/inbox/2.
The simple, first Sankey aggregations I wanted was the bowtie as in the image above. This would effectively be the pair:
SELECT 'FROM', COUNT(*) AS C WHERE 'TO'='mike.mcconnell' FROM ENRONMAIL GROUP BY 'FROM' ORDER BY C DESC; SELECT 'TO', COUNT(*) AS C WHERE 'FROM'='mike.mcconnell' FROM ENRONMAIL GROUP BY 'TO' ORDER BY C DESC;
Shove that into a basic Sankey and you're away. I wanted to make the full set and have them navigable by clicking on the names of the branches to recentre the bowtie. Initially, that wasn't possible but the StackOverflow community got me to the right remedy.
I used a modified version of the Sankey generator and iterated it a few times on the list of names it found to build a three-degrees from Rick Buy (or whoever) totaling 1826 names to then batch run the lot. Sankeyfying for those names took 2mins 12secs. That's fast enough to do on demand.
First pass at a batwing to just extend the left (from/from) helped with error discovery. Added lots of <namestring>.replace(/\'/g,""); for the O'Days, O'Haras, O'Keeffes and so on. I could've escaped them or like I have here, just dropped them.
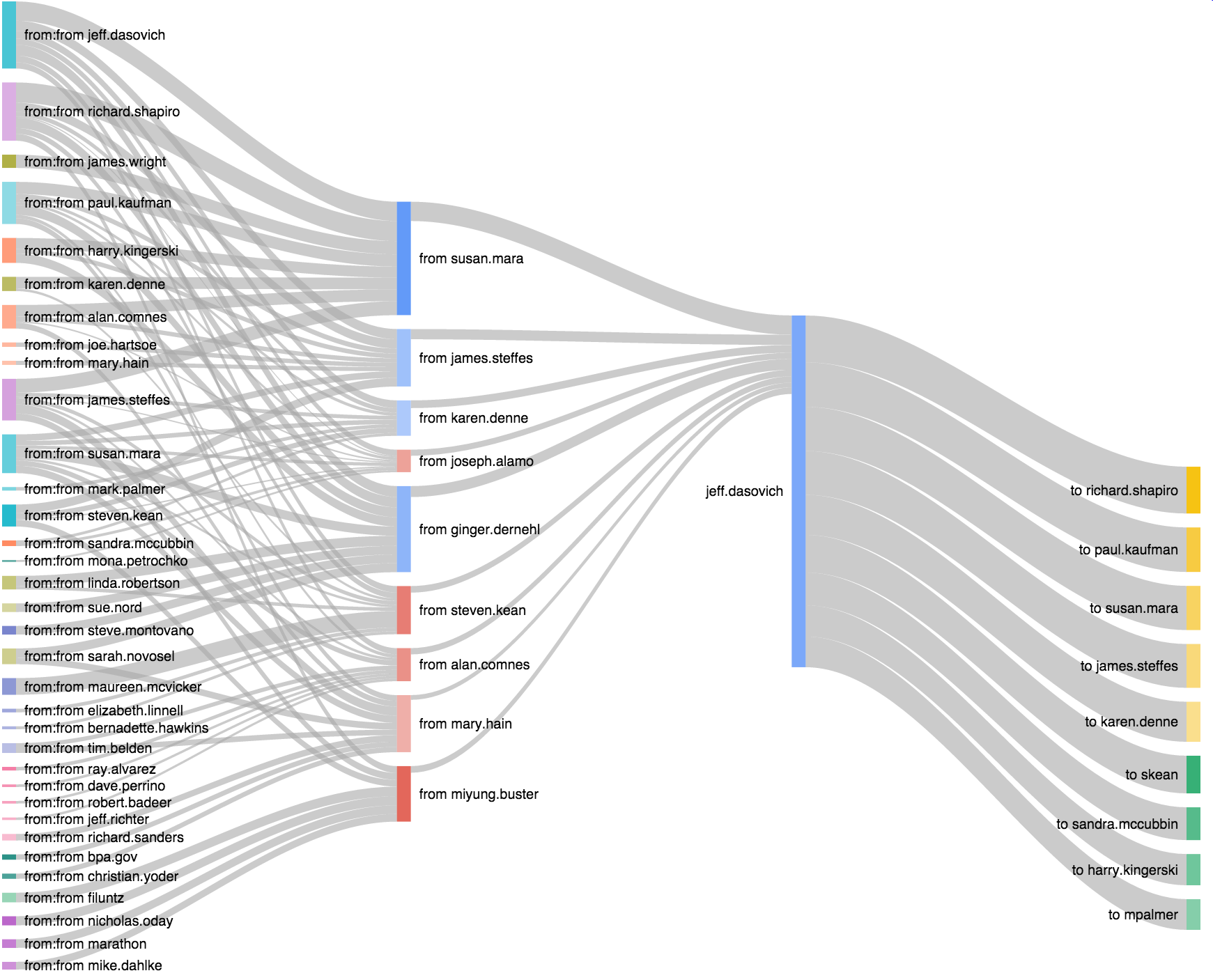
A matching set of batwings linked to bowtie Sankey views (click the centre namebar) generated in 2mins 59secs for twenty times as much work done in Elasticsearch. Still sub a tenth of a second each. Possible on demand then, probably while continually indexing new documents as they pass through the mail system.
JavaScript via the Food Standards Agency
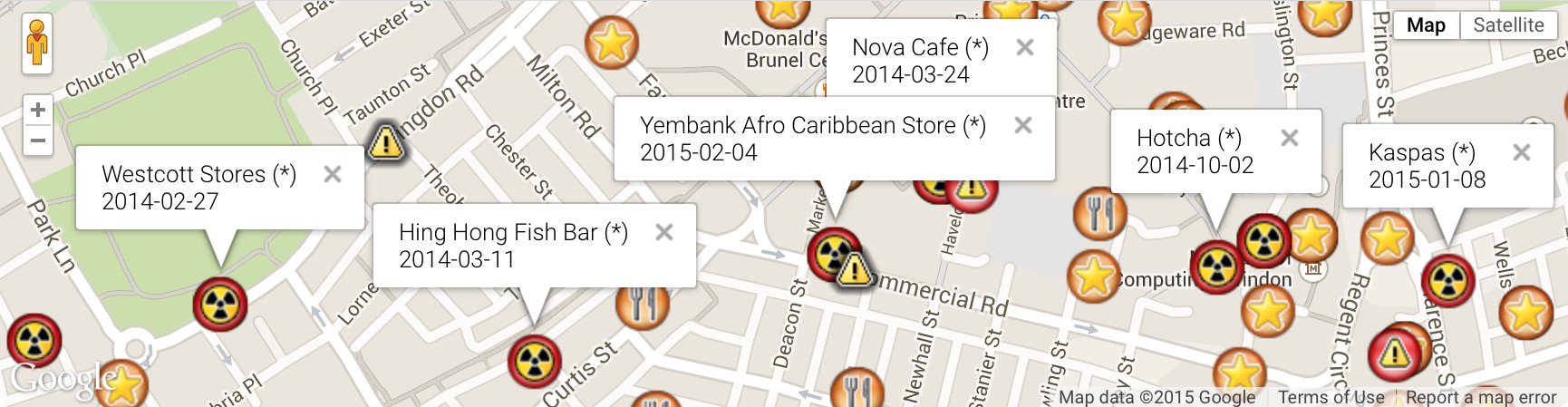
I wanted to learn a little JavaScript and being a non-UI person I did learnyounode until I thought I had enough to start something in anger.
FSA inspection ratings gathered by county pinned over Google's map.
JavaScript to generate static HTML set over Google's mapping API.
I wanted all the data, and it comes in XML and JSON options. Curl it in batches via
curl http://ratings.food.gov.uk/search/%5E/%5E/1/5000/xml
Where %5E (^) effectively means a wildcard for both the name of the county and the establishment that was inspected. Replace xml with json for JSON formatted equivalent. 1 is the page number and 5000 the page size. That's the largest page size I managed to collect -- for a total of about a hundred pages, the result includes metadata with the number of pages at your selected page size. The GitHub repo has an example HTML output for just the first 5000 elements.
As published, the data is partitioned into counties so I scraped the 406 files by curling the data page and piping it through grep http://ratings.food.gov.uk/OpenDataFiles/ | grep English to see something I could use cut to strip out the county names and the file names to re-curl. The GitHub repo has the xml data for North Somerset as a snapshot.
Google maps with pins are surprisingly simple. After installing xml2js to parse the xml with:
var xml2js = require('xml2js');
var parser = xml2js.Parser();
parser.parseString(data, function (err, result) {...
The inspection set for this county (loaded into data via fs.readFile()) is now navigable as a JavaScript object.
Wanting to avoid re-writing it with a cached set of jump-pins I bulk converted all the xml files to JSON with JSON.stringify() as the body to the callback of the xml2js::parser.parseString() function and exchanged the xml parser call to a JSON parser call (JSON.parse(data)). Took only a couple of minutes.